is an open-source Python package for the likelihood-based
estimation of parameters from measured data. Its selling points are
that it offers state-of-the-art statistical methods (e.g. confidence
intervals/regions based on the profile likelihood method),
that it only uses open-source software which allows users to
understand and reproduce results with relative ease,
and that it offers an easy-to-use and performance-optimized pipeline
that takes numerical data and produces for example parameter confidence
intervals or publication-quality plots.
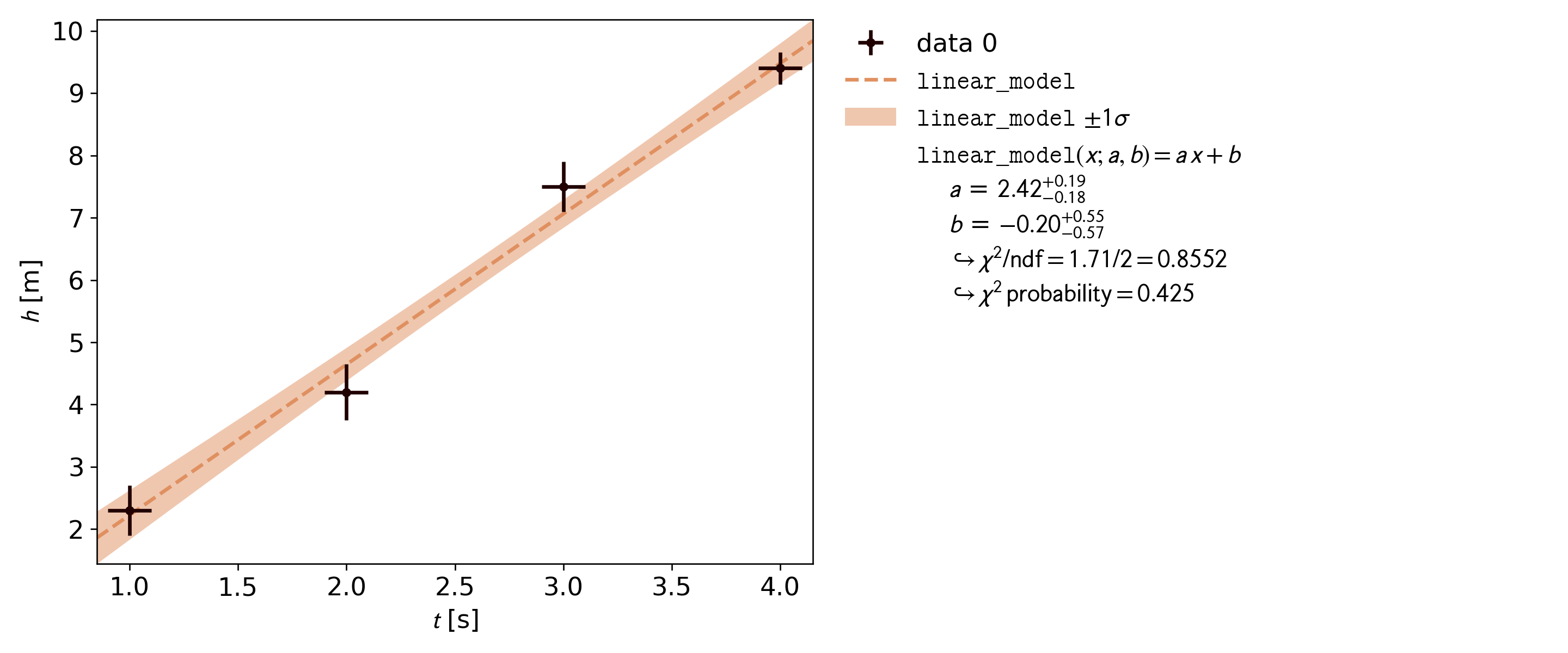
With just two function calls we get the following plot:
Example kafe2 plot
Ignoring imports and variable definitions the example consists of
just two function calls but a lot is happening under the hood:
A negative log-likelihood (NLL) function given the data and
uncertainties is constructed. Uncertainties in x and y direction can be
defined as either absolute or relative, and as either correlated or
uncorrelated. If a simple float is provided as input the same amount of
uncertainty is applied to each data point. Since the user did not
specify a model function a line is used by default.
A numerical optimization algorithm is applied to the likelihood
function to find the best estimates for the model parameter values.
Because the user defined uncertainties in x direction and
uncertainties relative to the y model values the total covariance matrix
has become a function of the model parameters. It is therefore necessary
to re-calculate the total covariance matrix at each optimization step;
while somewhat computationally expensive this ensures minimal bias and
good statistical coverage of the confidence intervals. Due to the
parameter-dependent uncertainties the regression problem as a whole has
also become nonlinear. kafe2 recognizes the change and switches
from estimating symmetrical parameter uncertainties from the
Rao-Cramér-Fréchet bound to estimating confidence intervals from the
profile likelihood.
The data and model are plotted along with a confidence band for the
model function. A legend containing information about the model, the
parameter estimates, and the results of a hypothesis test (Pearson’s
chi-squared test) is added automatically.
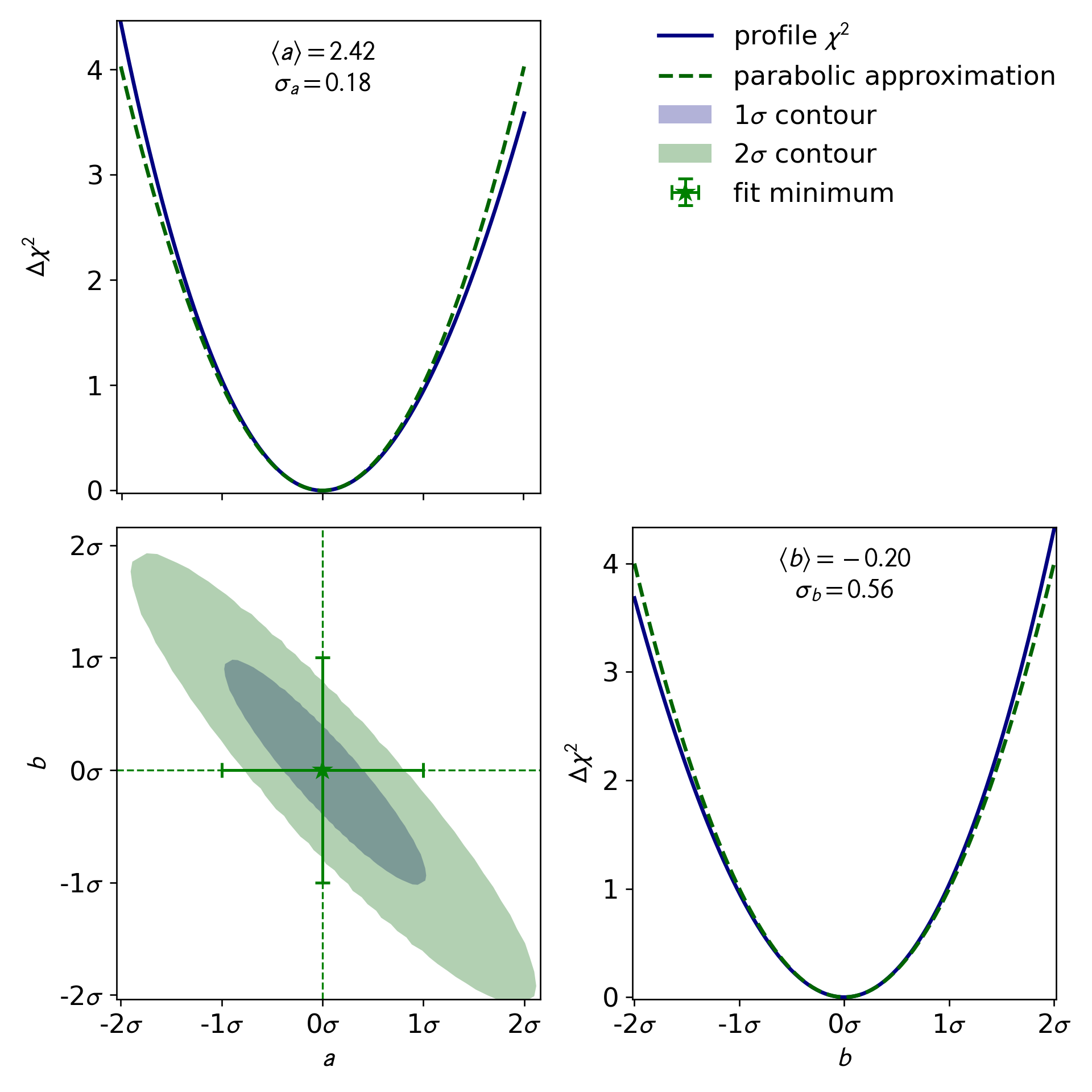
Because the regression problem is nonlinear kafe2 by
default also produces plots of the confidence intervals of single model
parameters as well as plots of the confidence regions of pairs of
parameters:
Example kafe2 plot of confidence
intervals/regions
The above example is of course highly configurable: among other
things users can define arbitrarily complex Python functions to
model the data, they can switch to different data types (e.g. histogram
data), they can use different likelihoods (e.g. Poisson), or they can
simultaneously fit multiple models with shared parameters. Since tools
have an inherent trade-off between usability and complex functionality
kafe2 offers several interfaces for fitting:
For users that have no programming knowledge a command line
interface “kafe2go” is provided. Users only have to write a
configuration file in YAML (a standard data serialization
language).
Slightly more advanced users that do have programming knowledge can
call the Python interface of the kafe2 pipeline as
part of a larger Python script.
Advanced users can construct custom pipelines by directly using the
kafe2 objects that represent for example data or plots.
By offering several interfaces with varying levels of complexity
kafe2 aims to meet the needs of both beginners and experts. To
learn more we invite you to take a look at the full
documentation.